
SBFT可以说是PBFT的扩展,它解决了扩展性(scalabillity)的问题,可以支持世界范围内的209个replicas(其中64个拜占庭错误replica)正常运行,并且吞吐量可以达到PBFT的两倍,延迟也更低。
//先写一下SBFT的论文总结吧,之后再更PBFT的。
INTRODUCTION
中心化提供了好的性能,但存在一系列问题,比特币和以太坊的成功说明了去中心化巨大的潜在价值。但是研究表明,比特币和以太坊并没有先前想的那么去中心化,前20%的矿池控制了超过90%的算力。这一研究说明了BFT算法应用于区块链的可行性(由于PoW过于消耗资源),也促使了BFT相关算法的研究。近年来BFT相关算法有替换掉PoW或者与PoW组合应用于区块链的趋势。
SBFT:a Scalable Decentralized Trust Infrastructure for Blockchains
SBFT为了做到这些性能上的提升,基于PBFT增加了四点设计上的改进:
(1)going from PBFT to linear PBFT
(2)adding a fast path
(3)using cryptography to allow a single message acknowledgement
(4)adding redundant servers to improve resilience and performance
1、From PBFT to linear PBFT
很多之前的系统都使用了多对多(all-to-all)的消息模式来提交一个确认区块,SBFT提出了一个使用收集器(collector)的线性通信模式。这种模式下不再将消息发给每一个replica,而是发给collector,然后再由collector广播给所有replicas。同时通过使用门限签名(threshold signatures)可以将消息长度从线性降低到常数。
//Zyzzyva也使用了collector,但是将collector的职责放到了client,而SBFT将collector的职责放到了replica。
2、adding a fast path
当所有replica都没有错误并且是同步(synchronous)时,SBFT允许使用快速共识机制。
SBFT实现了第一个正确且实用的双模式view change,可以在快速共识和正常共识之间无缝切换。
3、reducing client communication from f+1 to 1
在之前所有的解决方案中,client都需要收到f+1来自replicas的一致的reply才可以确认自己发出的request是否被执行。当client和replicas增多时,通信负载压力会增大。在SBFT中,正常情况下,每一个client只需要收到一个reply就足够了,这使得SBFT可以支持非常多的瘦客户端。
SBFT通过使用execution collector来做到这一点,execution collector收集replicas的execution threshold signatures并将其组合起来发送给client。像公链(比如比特币和以太坊)一样,SBFT也使用了默克尔树(merkle tree)来认证从某一个replica读取的信息。
SBFT使用了BLS签名,相比RSA签名,BLS只需要33个bytes就可以达到2048个bit(256个bytes)的RSA签名的安全性。
//八倍还是很可观的,当然BLS还有很多其他很有用的性质.
4、addding redundant servers to improve resilience and performance
当有f个拜占庭节点时,SBFT是安全的。不过只有当所有的节点都没有错误且系统是同步的时候才可以使用标准的快速共识,因此即使一个节点的故障都会使系统从fast path切换到slow path。
SBFT借鉴了single-shot consensus algorithm中提出的理论,使得fast path可以在3f+2c+1个replicas的系统中容忍c个故障replicas(这里,c是一个很小的常量)。
5、Evaluating SBFT’s scalability
由于目前没有什么可以和SBFT比的,于是作者改进了已有的PBFT算法,称之为scale optimized PBFT,作为比较对象。总之就是效果很好就是了。
SYSTEM MODEL
论文中讨论了三种模型:
(1)标准异步模式:敌人最多控制网络中的f个拜占庭节点、可以造成整个网络的延迟。SBFT可以保证safety,也就是任何两个replicas都会按同样的顺序执行同一个block。
(2)同步模型:敌人最多控制网络中的f个拜占庭节点。SBFT可以保证liveness,也就是client的request都会得到reply。
(3)一般模式:敌人最多控制网络中的c个慢的或者崩溃的节点。SBFT可以保证linearity,就是说每提交一个block只需要固定数量的消息(大概)。
MODERN CRYPTOGRAPHY
SBFT还使用了门限签名(threshold signature),对于n个replicas,只需要replicas的一个子集对block进行签名就可以验证。即子集中的replica分别使用自己的私钥签名之后再组合起来,最后可以只验证一次就可以了。
SBFT使用了比RSA签名算法更短更快的BLS签名算法,BLS基于椭圆曲线,有很多实用的性质,比如支持批量验证签名。
SERVICE PROPERTIES
SBFT提供了一个可扩展的通用复制服务的容错实现(也就是状态机复制服务),在这之上使用默克尔树实现了一个可认证的键值存储,又实现了可以执行EVM字节码的智能合约层。
1、Generic service
实现了确定的带状态的复制服务、确定的操作、只读的查询接口。
(1)val=execute(D,o):根据操作o修改状态D,并返回val.
(2)val=query(D,q):返回状态D下的查询q,不修改D.
(3)服务的状态由离散的block改变,每一个block包含一些request,论文中使用Dj表示执行完序号为j的block的状态,使用reqj表示序号为j的block包含的request.
2、A authenticated key-value store
为了支持client高效地认证来自某个replica的消息,在键值存储中设计了一些数据认证接口。
(1)d=digest(D):返回状态为D的默克尔哈希根的值作为哈希值。
(2)P=proof(o,l,s,D,val):返回序号为s的block中第l个操作o在状态D下(或者执行完后状态变为D)执行后的结果val的证明。
(3)P=proof(q,s,D,val): 和(2)一样,不过是查询q的证明。
(4)verify(d,o,val,s,l,P):如果序号为s的block中第l个操作o执行完毕后状态D的签名变成d,P是这一操作的有效证明,返回True。
(5)verify(d,q,val,s,P):同4。
3、A smart contract engine
这一层是为了以后方便集成其它智能合约语言。目前的EVM layer实现了两个主要组件:
(1)EVM的实现;
(2)实现一个接口,完成对以太坊两个主要交易类型(创建合约&&执行合约)的建模。
SBFT REPLICATION PROTOCOL
整个系统有3f+2c+1个replica,编号从1到3f+2c+1。使用了三个门限签名:
(1)σ with threshold (3f+c+1)
(2)τ with threshold (2f+c+1)
(3)π with threshold (f+1)
和PBFT一样使用了view change协议,每一个view有一个primary,其它repplica是backups。与PBFT不同的是,这些backups还拥有其他身份,Commit collectors和Execution collectors。每一个view中都会有c+1个Commit collectors和Execution collectors用来收集并组合门限签名和传播结果签名。为了实现liveness,至少需要一个collector,论文中在fast path情况下用了c+1个collector实现冗余。
Commit collectors的作用是收集提交消息,并将组合的签名发送回副本以确认提交。 Execution collectors的作用是收集执行消息,并将组合的签名发送回副本和客户端,以便它们都具有执行其请求的证书。
1、SBFT在fast path下的工作流程
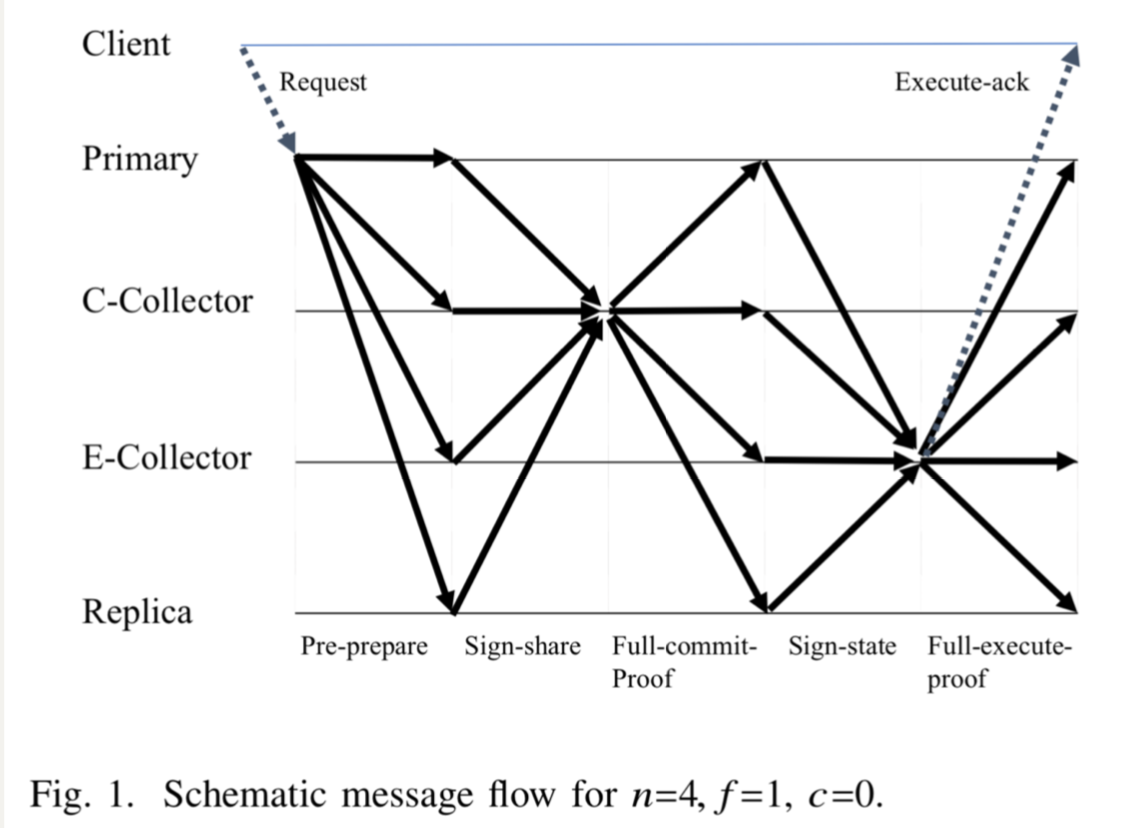
(1)client向primary发送request
(2)primary收集request,将其打包成block,并作为pre-prepare message转发给其他replicas
(3)replicas对收到的pre-prepare message使用σ(3f+c+1)签名,然后将签名消息发给C-collectors.
(4)每一个C-collector收集签名,为该block创建一个full-commit-proof消息发给replicas
一旦replica收到full-commit-proof消息,它就commit这个block,然后开始执行execution protocol:
(1)当replica执行完提交的block之前的blocks,它执行这个block中的request,并使用π(f+1)进行签名,然后发送sign-state message给E-collectors
(2)E-collector收集签名,并为该block创建一个full-execute-proof ,然后告诉replicas和client当前状态是持久的并且操作已经被执行。
SBFT通过对给一个decision block选不同的E-collectors和C-collectors来实现负载均衡。
2、The Client
client k 通过发送⟨“request”,o,t,k⟩消息给primary,primary再转发给backups,开始共识。
先前的系统中client需要等待f+1个replica才完成确认,SBFT中只需要一个
⟨“execute−ack”,s,val,o,π(d),proof(o,l,s,D,val)⟩消息就可以确认。如果client等待超时,就会将该request发给所有的replicas。
3、The Replicas
replica的状态包含一个记录所有消息的log,状态还包含了视图编号、上一个稳定的序号(last stable sequence)、执行完所有commited requests后服务的状态D。还使用了一个固定值win限制超前太多的block。
有的replicas还担任C-collectors或则E-collector,执行特殊的任务。
4、fast path protocol
fast path protocol是执行的默认模式,可以在不超过c个crashed/slow replicas的同步环境下正常运行。
为了commit一个新的block,primary开始执行一个三阶段的协议:pre-prepare、sign-share、commit-proof.
(1)pre-prepare阶段:
primary收到来自client k的⟨“request”,o,t,k⟩(如果操作o通过静态服务认证和访问控制规则就接受),当收到至少b个(b≥batch)client发来的request(或者超时)后,将这些request打包到集合r=(r1,r2,…,rb).然后广播⟨“pre−prepare”,s,v,r⟩
⟨“pre−prepare”,s,v,r⟩给所有的replicas。其中s是当前的序号,v是视图号。batch这个参数是通过自适应算法设置的。
(2)Sign-share阶段:
replica收到⟨“pre−prepare”,s,v,r⟩消息后,进行检查,满足条件(具体条件参考论文)就接受。然后计算h=H(s∣∣v∣∣r),其中H是一个加密哈希函数(比如SHA256),接着对h进行签名σi(h),最后发送⟨“sign−share”,s,v,σi(h)⟩消息给那些C-collectors <C-collectors(s, v)>.
(3)Commit-proof阶段:
C-collectors(s,v)收到⟨“sign−share”,s,v,σi(h)⟩后,进行检查,当接受3f+c+1个不同的sign-share消息时,将这些消息组合成一个大的签名σ(h),然后发送
⟨“full−commit−proof”,s,v,σ(h)⟩给其他replicas。
(4)Commit trigger阶段:
replica收到⟨“full−commit−proof”,s,v,σ(h)⟩消息后,检查,确认接受,然后commit r(r是序号为s的请求)。
5、Execution and Acknowledgement
与先前的其他算法主要的不同在于使用了门限签名。一旦replica收到committed的block,就启动一个两阶段的协议:sign-state、execute-proof.
(1)Execute trigger and sign state:
当收到committed的block(序号为s)后,replica_i执行request将状态从Ds−1更新到Ds。然后更新状态摘要d=digest(Dx),签名πi(d),最后发送⟨“sign−state”,s,πi(d)⟩消息给集合E-collectors(s)。
(2)Execute-proof:
E-collector收集⟨“sign−state”,s,πi(d)⟩消息并验证签名,当收到f+1个时,将其租着成一个签名π(d),发送⟨“full−execute−proof”,s,π(d)⟩消息给所有的replica,replicas检查签名决定是否接受。
然后E-collector对每一个request o∈r,发给client一个
⟨“execute−ack”,s,l,val,o,π(d),proof(o,l,s,D,val)⟩,其中是o的返回值。client接收
⟨“execute−ack”,s,l,val,o,π(d),P⟩消息后,检查π(d)是否有效并且verify(d,o,val,s,l,P)是否为真,确认有效后client标记o已执行,将val设置为返回值。如果client超时就重发该request,进行正常共识。
6、Linear-PBFT
当fast path无法达成共识时,就使用Linear-PBFT。Linear-PBFT是对PBFT的改编,使用了门限签名和线性通信。
(1)Sign-share:
需要包含两个签名,σi(h)(for fast path)和τi(h)(for Linear PBFT path)
(2)Trigger for Linear-PBFT:
根据过去的流量情况采用自适应算法确定一个等待时间,如果超时就切换到Linear-PBFT。C-collector收集签名,创建τ(h),如果超时,就发送⟨“prepare”,s,v,τ(h)⟩给所有replicas。
(3)Prepare:
replica收到⟨“prepare”,s,v,τ(h)⟩消息并进行检查,如果通过检查就发送⟨“commit”,s,v,τi(τ(h))⟩给所有C-collectors。
(4)PBFT commit-proof:
C-collectors收集足够的签名来创建⟨“full−commit−proof−slow”,s,v,τ(τ(h))⟩消息,发给所有replicas。
(5)Commit trigger for Linear-PBFT:
如果replica收到⟨“full−commit−proof−slow”,s,v,τ(τ(h))⟩和⟨“pre−prepare”,s,v,r,h⟩
消息,验证通过h=H(s∣∣v∣∣r),然后就commit r(r是block s 包含的request)。
7、Garbage Collection and Checkpoint Protocol
block s 有三种状态:
(1)Committed:至少一个正常的replica commit了该block
(2)Executed:至少一个正常的replica commit完了1到s的所有block
(3)Stable:至少f+1个正常的replica execute了该block
当一个block状态时Stable时,可以收集先前的block。像PBFT中一样,每隔一定周期(win/2)进行一次checkpoint protocol,更新ls (the last stable sequence number).
8、View Change Protocol
SBFT中有两种commit模式,Fast-path和Linear-PBFT。
先前的方案需要显式地指出使用哪一种模式,SBFT提出了新的View Change Protocol,支持同时运行两种模式,并无缝切换。
(1)View change trigger:
当计时器超时或收到其主节点有故障的证据(通过公开可验证的矛盾或f + 1个副本抱怨)时,replica会触发视图更改。
(2)View-change 阶段:
(3)New-view 阶段:
新主节点从replicas收集2f+2c+1个view-change消息,通过发送一个消息(2f+2c+1个view-change消息的集合体)来初始化一个新view.
(4)Accepting a New-view:
当节点收到集合I( 2 f + 2c + 1视图更改消息)时,它一一处理从ls(所有视图更改消息中的最高有效稳定序列号)到ls+win的slots。对于每个这样的slot,根据以下算法,节点要么决定可以提交值,要么将其用作新的主节点的pre-prepare消息。
如果节点收到σ(⋆)或τ(τ(⋆))),则由节点决定。否则,它采用安全值(参见论文)。安全值y是由最高视图而得到的值,对于该最高视图,可能存在在先前视图中可能提交的潜在值。要定义此视图,需要仔细定义两个提交路径中的每一个都具有值的最高视图,然后在这两个路径之间采用最高视图。如果没有需要采用的值,我们将使用特殊的无操作操作来填充序列。

如果FX包含σ(h)或LX包含τ(τ(h)),则让y为h并在知道消息后提交。否则:

(5)Efficient view change via pipelining:
SBFT允许在序列号<x的pre-prepare信息到达之前提交序列号x。这使SBFT具有高度的并行性。
像PBFT一样,在视图更改期间,SBFT需要为ls和ls + win之间的每个序列号建议一个值。另一种方法是仅在所有≤x序列号的所有pre-prepare消息到达后,并且x的哈希值代表整个历史记录(即,$h_x=H(r || s || v || h_{x-1})$)之后,才提交序列号x。这意味着,当主节点提交序列号x时,它将在同一决策中隐式提交所有≤x的序列号。
通过这些更改,我们可以进行更有效的view-change。对于新的主节点来说,无需为从ls到ls + win的每个序列号发送带有证明的pre-prepare的值,只需从每个副本中收集两对信息就足够了。

和之前一样,主节点收集2f+2c+1这样的消息,并从(v,h)和($v’,h’$)中选择最高的视图(如果有平局,则首选(v,h))。
这种视图更改的优点是,无论窗口大小如何,仅发送两个值。
//todo:safety和liveness的证明
实现:https://github.com/vmware/concord-bft
Anyway,Fighting is right!